
Polymeric molecules are all around is and in us. It is hardly surprising that a large fraction of life’s molecules carrying information are polymeric, from DNA, RNA to proteins, lipids and peptides.
During my PhD I fell in love with polymers. (I had started my Phd work in Quantum Information but would quickly switched to soft-matter physics). I worked on Vulcanization Transition, a second-order phase transition in which a random melt of polymers, like natural rubber, can be chemically cross-linked to form random solids. I later became fascinated by gels, glassy solids, and the deep connections of their physics to percolation theory, random-resistor networks and jamming transition.
Over the years, I met another fascinating polymer called oligonucleotide: bits of RNA, double-stranded or single stranded (shRNA & siRNA) and eventually bits of DNA (Anti-Sense Oligonucleotides, or ASOs). Oligonucleotides are informational drugs. They carry the genetic information they are destined to modulate.
We all witness the impact of another such informational medicine during Covid-19, the synthetic mRNA polymer creating the right fragment of a protein to vaccinate. If you think about it, 3 of the 4 medicine modalities are polymers: peptides, antibodies, nucleic acids. Small molecules are the only exception; they carry nebulous information lacking focus and interact with almost everything.
Yet, we understand so much and so little about polymers! When I cofounded Creyon, my dream was to engineer one kind of polymer really well: oligonucleotides. These are bits of nucleic acids that are chemically modified to make them drug-like (functionalization), that can be sent to a cell or tissue and precisely control gene expression! (Isn’t it marvelous that A, C, G, T code, a quad, instead of a bit, could do that? It could manipulate the very information in genes that I need to even see this screen?) These functionalizations—chemical modifications of the base, linker of sugar unit of the nucleic acid— could fundamentally change their biological, physical, biochemical properties. They could make these polymers more or less viscous, soluble, serum stable, immunotoxic, bioavailable; sometimes modulating pharmacology measures across four orders of magnitude by a single modification on the same base sequence! We were engineering these molecules & manipulating the information in the informational drug across several axis. We learned how to make the information allele-selective, well-tolerated, have higher affinity, have higher on-rate or activity, and so on.
Lately, I have expanded the scope of that lifelong dream of controlling information flow. The scope is not just human biology and disease, but what more can sequences do and how well can we create sequences? Obviously, a lot of changed in the last 2 yrs! As society we have marveled at what AI can do when fed a large corpus of textual sequences. Who knew LLMs could get this good at writing not just text sequences but logical sequences of codes?
Polymers are just chemical sequences.
Well, one challenge is data. Where are all the data to learn the properties of molecules? Molecules inhabit a very special world. Unlike textual sequences where correlations are hard to quantify but easy to sense, correlations in molecules follow the laws of quantum physics, easy to validate and quantify, but hard to sense by intuition.
The bad news is we need to create these physics-faithful datasets. But the good news is the correlations are nearsighted, as Walter Kohn called it Quantum Nearsightedness.
We started dreaming that we should be able to predict physical properties, like conformations, free energy etc. purely from chemical sequence of polymers. As with any dream, you need good partners in crime! David Pekker Todd Martinez
We tried to take the simplest first step.
Can we predict the thermal ensemble of polymer conformations from their sequence alone?
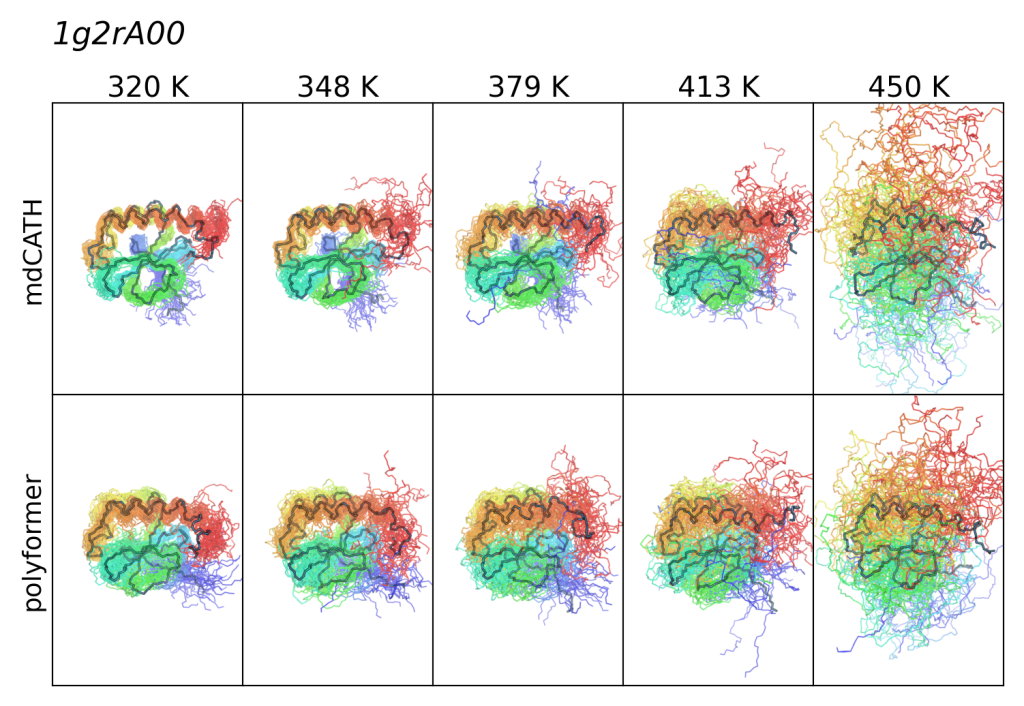
Well, we asked ourselves, what is a realistic system that will stress test this unreasonable dream? We tinkered with some internal data, but settled on a large dataset on MD trajectories of peptides that was freely available (mdCATH dataset). The trajectory sampling in this data is almost certainly not ergodic, but hey, beggers can’t be choosers, right? Do you have 1-5 Million GPU hours to spare? If it were fully ergodic, we would have gotten very close to computing free energy of peptides directly from sequence. Wild, right?
What we discovered, once we figured out a few critical things in how to include the physics the right way into Diffusion Transformers, that we were able to predict the conformation ensemble as a function of temperature. We did some other work internally to convince ourselves we could do this for other systems too, like for concentration dependence.
So why care?
Turns out, properties of polymers are driven by their conformations and free energy. Ask any peptide chemist and she will tell you that controlling the degrees of freedom (by macrocyclization) is what with you do once you have a lead molecule to stare at and a glass of wine to place some educated chemical bets. Ask a nucleic acid chemist, and she will tell you that a blessed hairpin structure is the reason that an aptamer is a molecular beacon.
But here is the inconvenient truth. Oligo-length (meaning ~10-100 monomer long) polymers (peptides included) are very often highly flexible, and it makes no sense to anchor your expectations of their properties on a single low-energy conformation. Larger proteins are probably a bit different; some of them are folded by chaperones, and it makes sense to use an AlphaFold/ESM/SimpleFold predicted single or closely related structure.
So what next? Well, if we can predict physical properties from sequences, I think an analogy is worth entertaining:
If LLMs understand text and we are increasingly fasciated by teaching LLMs Physical world (Newtonian) what does it take for a Molecular AI model like ours to understand the Quantum World of molecules? How much data? What kind of “sensors” are analogous to the Physical AI sensors and cameras?
And most importantly, were is the limits of molecular engineering? Will you laugh at me if we dream about predicting viscosity? Conductivity? If we engineer the perfect conductive polymer using such generative tools? The perfect tissue-targeting molecule? The perfect precision medicine, ready to be printed?
Read the paper and criticize. We are just getting warmed up! Send your comments!
- https://arxiv.org/abs/2604.14241: Polyformer: a generative framework for thermodynamic modeling of polymeric molecules

Leave a comment